超高速開発コミュニティ モデリング分科会「単独主キー主義」の是非を問う に参加してきました。
去る6月28日、超高速開発コミュニティモデリング分科会「単独主キー主義」の是非を問う
に参加してきました。開催ありがとうございました。
この会は、渡辺幸三さんの最近のブログエントリ
「単独主キー専用環境」と賢くつきあうために
http://watanabek.cocolog-nifty.com/blog/2017/05/post-578f.html
に呼応して開催された勉強会のうちのひとつです。
(※この他に、IT勉強宴会さんでも、5月12日に、「複合主キーは必須なのか?」というテーマで 第55回IT勉強宴会Light というのが開催されていました。行けなくて残念。)
「単独主キー主義」の是非 と言われても、そこから何を想起するか、めいめいバラバラでしょうね。まずは用語を整理します。
これについては明快な答えを、渡辺さんが最初に提示してくれました。
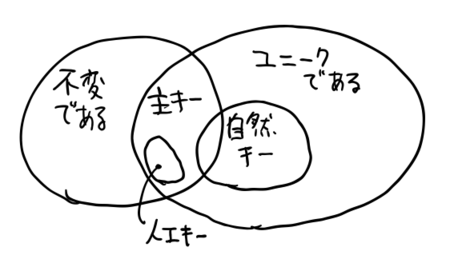
超わかりやすいですね。
そして、「単独主キー専用環境」とは、例えばRubyOnRailsのように、主キーが単独のカラムであることを制約づけた実装環境のことを指しています。
で、通常、データモデリングは、こういった実装環境からはある程度(あるいは厳格に)独立して成立するはずなのですが、そのデータモデリング時点においても、主キーが単独であることを志向する考えかたはあり、それを仮に「単独主キー主義」と呼ぶことにします。
といった前提の上で、「単独主キー主義」の是非について意見を述べ合うという会でした。
参加レポート
まずは「単独主キー主義」の実例として渡辺さんが挙げてくれたのが以下の例でした。ある会社内で、例えば「社員の趣味」を管理したい、という要求があったとして、そのデータ構造は、リレーショナルDBのテーブル上、おそらく以下のようなものなるでしょう。
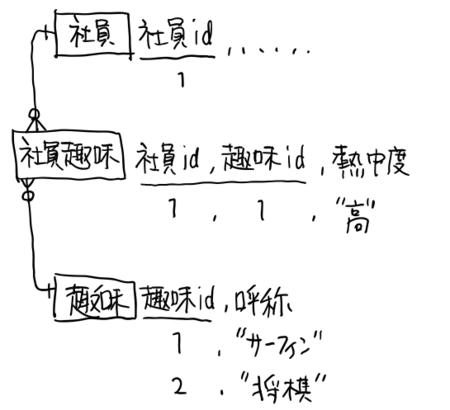
※下線が主キーです。
特に難しいことはないですね。社員のアイデンティファイアと趣味のアイデンティファイアとを複合したものが、"社員趣味"のキーであるという解釈です。
これが、「単独主キー主義」によると、おそらくこうなるであろう、と。

※波括弧は候補キーです。
これもぱっと見、特に違和感ありません。RubyOnRailsでの実装が前提ならこうなるでしょう。しかし問題はその先に潜在しています。{社員id, 趣味id} という、意味上の主キー2項に対して、
ユニーク制約は設定されてはいたとしても、実装上の主キーではない。ので、"趣味id" がなんらかの機会に書き換えられてしまう可能性がある。つまり「不変かつユニーク」という主キーの要件を満たせない状態になっているわけです。
「この場合は、ユニーク制約に加えて、何らかの方法でこれらの項目を更新不可にすればよいのでは?」
と言われれば、その通りではある。とはいえ、そこまでしなきゃいけないんだったら、そもそも無用な代理キーなど無しで実装させてほしい気持ちがある(物理的心理的コストの負荷)。
何より、こうした潜在的な問題に事前に気付いて対策できればまだいいが、
不整合データが実際に発生するまで問題に気付かなかったり、
不整合データが実際に発生してもそれに気付かなかったりしたら
目もあてられないではないか。それって設計したといえるの?
というのが渡辺さんの問題提起でした。
この問題提起を皮切りにディスカッションが始まったんですが、ほんとにどれも興味深い意見ばかりでして
- 単独主キーオンリーの実装からは、確かに業務は分析しにくい。
- データの制約を実現する箇所はリレーショナルDBだけではない。
いろんなアプリケーションが同じDBに自由に接続するという状況は今や稀。
DBを読み書きするアプリケーション層あるいはAPI層がひとつであるのなら、
その層がデータの整合性に責任を持てばいいという作り方もできる。- いまやいろんなデータストアがあり、それらがすべて
リレーショナルモデル的に適切な制約を実装しているとは限らないし。
- いまやいろんなデータストアがあり、それらがすべて
- お客様が要件をなかなか決めきれないことはよくある。その条件下で「とりあえず」の
単独主キーを設定して、モデリング→実装まで進めるという便法はアリかも。
- データモデリングがお客様との共通言語になりにくいという壁はあるよね。
- そこで、"動くモデリングツール"(X-TEA DriverやTALONなど)ですよ。
- 矛盾や間違いに気づきやすいというメリットはやはり強力。
- そこで、"動くモデリングツール"(X-TEA DriverやTALONなど)ですよ。
- Salesforceは、ぱっと見単独主キーの世界だが、エンティティ同士の親子関係を指定するメタ情報がある。
それがあるから厳格なモデリングもできるようになってはいる。
- 例えば社内SNSがいくつもあるような状況下では、適当な単独主キーによる"ユーザー"データが、
あちこちの別システムにに散らばることになる。それらは名寄せして初めてほんもののユーザーデータが
表現できるので、各々のユーザーデータの主キーは仮のものであるのはむしろ自然な姿かも。
- TM(T字形ER手法)では、「社員趣味」はそもそもエンティティとして扱わない。
そこにアイデンティファイアが無いから。エンティティではなく"関係"。
レポートと銘打ってみたものの、ちょっとうまくまとめられそうにない。ので、この箇条書きを提示するにとどめますね。
落穂拾い
ところで、ここで、最初の「社員の趣味」のモデリングについてもういちど検討してみたいと思います。そもそも、{社員id, 趣味id} って、本当にこのエンティティの主キーなんでしょうか?
いや、そもそも、「社員趣味」って何でしょう?
例えば、ある社員は過去に、カメラにものすごく凝ったことがあるとしましょう。それを根拠に「趣味は写真です」と言ってもいいし、あるいは、それは過去のことだから、もう写真は趣味じゃない、という結論でもいい。もう趣味じゃないから放っておくかもしれないし、もう趣味じゃないから、データを更新しないと!って思っているかもしれない。
という状況下で、この社員の趣味について、このテーブルのデータから何が読み取れるだろう?
なんだかすごく曖昧だ。「社員趣味」っていうエンティティが表現しようとしているものが曖昧。
あっ、だから主キーが見つからないんじゃないの?
では試みに、このエンティティのあり方を再定義してみましょう。
もしこれが「社員の趣味」ではなく、「会社の朝礼で、社員が自分の趣味についてスピーチした記録」だとしたら?
その場合、日付なり、朝礼エンティティのアイデンティファイアなりが候補キーに入ってくるでしょう。主キーの再定義です。

この新しい「社員趣味カミングアウト履歴」エンティティは、イベントの記録なので、ユースケース上、書き換えは発生しません。
もちろん、なんらかの理由で趣味idが書き換えられてしまう可能性は依然、ゼロではありませんが、当初の「社員趣味」エンティティよりもだいぶ安定を感じます。
(※そして、イベントというのは、それを参照する何かが居るから記録するわけです。なので、その参照の便宜をはかるための代理キーの存在理由も、若干正当性を増したように思います。)
何より、「社員の趣味」を正しく把握しやすくなりました。
最新の一件を、「現在の趣味」と位置づけるのもいいし、すべての趣味を拾い出した上で、その日付の新しさを見て、趣味群に重み付けをしてもいいし。
主キーについて考えることは、エンティティについて考えること、ひいては、データの目的について考えることと同時点なんですね。
渡辺さんが何気なく出したように見えたこの仮想の事例、こうして軽く掘ってみたら、今回の勉強会の本質にきっちり回帰することになってびっくり。ちょっと出来過ぎじゃないですかね。
まとめると
このようにデータモデリングという作業は、発見が多くて面白いです。問題を解決するプロセスは、問題を理解するプロセスとニアリーイコールなので、その意味でデータモデリングは僕にとっては欠かせないプロセスです。
(※データモデリングを省略する適切なやり方や、その意味が明らかになる日がもし来たら、それはそれで面白そうですが。)
データモデリングに触れたことが無いという技術者の方こそ、こういった勉強会に来てほしいですね。本を読んで独習するよりはるかにはかどるし、エキサイティングですよ。