DynamoDBにおけるデータベース設計手法(の断片)
AWS DynamoDBにおけるデータベース設計について、(例えばリレーショナルモデルのように)一般化された理論を基に述べているものが見つけられない。
せめて、リレーショナルモデルと比較するかたちででもNoSQLのデータベース設計の手法を言語化してみてはどうか。それがこのエントリです。
本稿であつかうテクニックは以下のふたつを実現するものです。
- DynamoDBの制約の中で、それでも目的の検索を可能とするインデックスを構成する。いわゆる”タテ持ち”に近い手法を用いることで。
- テーブルの全体数を減らす。リレーションを、RDBとは違う方法で表現することで。
2.について少し補足しておきましょう。実は、テーブルの全体数を減らすことが重要なのではありません。 そもそもNoSQLではテーブルが特定の型を持たないので、型の違いをテーブルの違いで表現する理由が無いんですね。 あらゆるエンティティをたったひとつのテーブルに格納することも出来るわけです。そんなデータベース設計が人間に理解しやすいとは僕には思えないので、この最も本質的なポイントは本稿ではあえて重要視しません。ただ、テーブルの数を減らすことはNoSQLにおいては必然の習慣であるのは確かです。
行に関数従属した任意の項目群を、絞り込みまたはソートのキーにする
特に、この絞り込みが範囲検索である場合に、以下に述べるような工夫が必要になってきます。
例えばブログシステムの記事テーブルに、公開開始日時と公開終了日時があり、これらの値を使った記事一覧取得処理について考える場合、以下の手順による準備が必要になります。
- 行の中から、絞り込みまたはソートのキーに使いたいkey-valueペア群を切り出す。

テーブルは、複合主キー型のテーブル、つまりソートキーを持つタイプのテーブルとする。ソートキー列は文字列型で列名は、例えば "indefinite" とする。つまりどんな値が入ってくるか不定な列である。

切り出した部品に型としての名前をつける(例えば "for_search")。この名前を
indefinite列の値とし、pertition-keyの値はオリジナル行と同一としたうえで、切り出したkey-valueペア群を派生行としてテーブルに挿入する。
派生行の型の中から、任意の項をHASHキーまたはRANGEキーにしたGlobal Secondary Index(以下GSI)を構成しておく。RANGEキーにするなら、それと組になるHASHキーには
indefinite列を指定するのが妥当だろう。

この設定の結果、記事テーブル上の二つのインデックスによって、
- 公開開始日時が現在日時より小さく
- 公開終了日時が現在日時より大きく
indefinite列の値が"for_search"である
という条件での絞り込みが可能になりました。絞り込んだ結果には少なくともpertition-key、つまりエンティティの主キーの値が含まれるようになります。
それ以上の属性値、例えばタイトルを含ませたいのであれば、オリジナル行から
{ title: "1月10日の日記" }
の項も、"for_search" 行にコピーしておく必要があります。(その場合当然、コピーしたkey-valueペア群の更新整合性は失われるわけですが)
ManyToManyな関係を交差テーブルを使わずに表現する
お馴染みの、FilmとActorの関係で考えましょう。

このFilmテーブルの側に視点を置きます。
これをNoSQLの流儀で表現するには以下の手順を必要とします。
- Actorテーブルの主キー / Filmテーブルの主キー / Actorテーブルの型名
の3つの要素を含むkey-valueペア群を、同一
pertition-key値に紐付く派生行としてテーブルに挿入する。テーブルの構成は上記の例と同様、複合主キー型のテーブルとする。派生行のindefinite列の値には、Actorの主キー値またはそれを代理する値を充てておく。
- Actorテーブルの主キーをHASHキーにしたGSIを設定する。これによって、Filmテーブル上で、Actorの任意の主キー値から、関係するFilmの主キー値群が取得できるようになる。


- 派生行内のFilmテーブルの主キーと、Actorテーブルの型名、の組からなるGSIを構成する。これによって、Filmテーブル上で、Filmの任意の主キー値から、関係するActorの主キー値群が取得できるようになる。(なお、扱うOneToManyが一種しか無いと分かっている状況下であれば、"Actorテーブルの型名" は不要)


まとめ
今回紹介した手法を一般化して言うと、以下のようになるでしょう。
- DynamoDBの基本部品である、“2項から成る複合主キー”のうちの一方に単独主キーの値を、もう一方に任意の固定値を与えることで、ひとつの主キー配下に意味の異なる派生行を構成できる。その用途は例えば検索やソートのためのキーの設定など。この派生行はいわば、OneToOneの関係を持つテーブル同士をひとつのテーブル上で表現している状態である。
- DynamoDBの基本部品である、“2項から成る複合主キー”のうちの一方に単独主キーの値を、もう一方にManyToManyの関係先の主キー値またはそれを代理する値を配することで、関係そのものを表現が出来る(つまり交差テーブルに相当するもの)。これはOneToManyやManyToManyの関係を持つテーブル同士をひとつのテーブル上で表現しようとしている状態といえる。
ひとつの主キー値配下に、用途別に複数の行を持たせるというやり方は、リレーショナルモデルに慣れた脳にはとんでもない無法に見えますね。行の概念を完全に覆しているので。つまりNoSQLにおけるテーブルとは、実はテーブルではなくて別のものであるということが、このことから分かるわけです。
NoSQLでは、ひとつのテーブルに型の異なるタプルを同居させられる。ゆえに、
- ある行の型を基にしたインデックスがすべての行にわたって作用するとは限らない。
- しかしテーブルの(複合)主キーは存在している。これはすべての行にわたって作用するインデックスとなる。
この2つの特徴を踏まえることで、テーブルの数を圧縮しつつ、関係を表現し、且つインデックスを自在に構成することが出来ました。
思い返せば、初期のGoogle AppEngineを扱ったときも、NoSQL上でいろんな工夫をして問題を解決しました。その記録を辿るのも困難なくらい時間が経ってしまい、工夫の数々は事実上、無に帰したわけです。その反省もこめて書きました。
Alloy Analyzer で状態の変化を表現する方法
alloyで状態の変化を表現する方法はいろいろありますが、なるべく単純なかたちでこれを実現してみたいと思います。
ことを目的とします。
なお状態変化を引き起こす、イベントについては、ここでは表現しません。
状態表現用のフィールドを付加する
単純に、上記の2要素をフィールドに落とし込みました。つまり、事前/事後の状態あらわすフィールドと、識別子としてのフィールド、を用意することで、状態の変化は表現できるはずです。
module main // Boundaryは、何らかの1次元の位置、つまり何らかの値を表す。 sig Boundary { val: one Int } sig Entity { some_field: one Boundary, // 状態変化を表現することを目的に付加したフィールド meta_id: one Int, meta_state: one Int } fact { /** meta_state は、-1か0しかない。つまり、事前と事後。*/ all e:Entity | e.meta_state = 0 or e.meta_state = -1 /** ID が等しいふたつAtomがあったら、 それはひとつのAtomの事前状態と事後状態であると考える。 */ all e1,e2:Entity | (e1 != e2 and e1.meta_id = e2.meta_id) => (e1.meta_state != e2.meta_state) } run {} for 3 but 4 Entity, 3 Int
すると、こうなります。
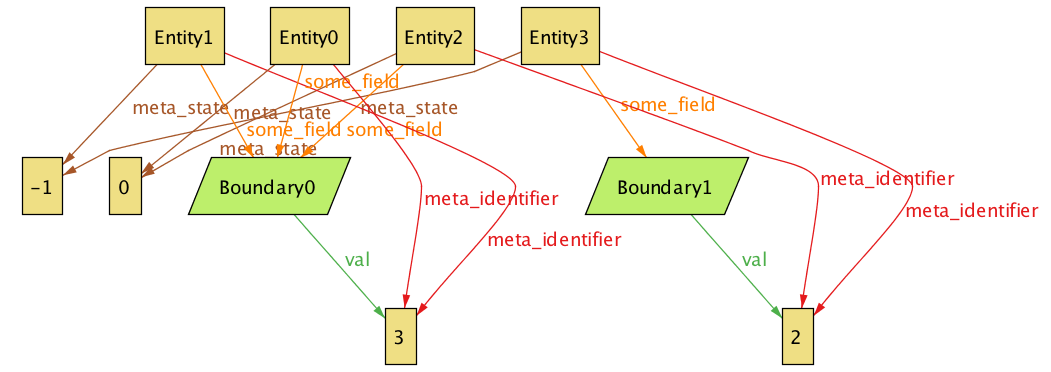
Entity0はEntity1が、Entity3はEntity2が状態変化したものである、ことを示しているといえます。
しかし、ちょっとまってください。
確かにEntity2は、Entity3に状態が変化しているといえます。その証拠に、"some_field" の値が変わっています。
しかし、Entity0は、Entity1と較べて、値は何も変わっていません。これは状態変化したと言えないのではないか?
その通りです。
「何を以って状態が変化した」とするのか、その定義が無ければ筋が通りませんね。
それも記述しましょう。ついでに、状態変化の対象となるAtomと、ならないAtomがあるというケースにも対応します。
上記のalloyモジュールにさらに編集して
たとえば以下のように、くじ引きをモデリングしてみます。
<抽選前>
- 参加者は、重複の無いユニークな抽選番号をひとつづつ与えられている
<抽選後>
- 一番大きな抽選番号を持っていた参加者が、賞品を得ている
module main // Boundaryは、何らかの1次元の位置、つまり何らかの値を表す。 sig Boundary { val: one Int } sig Participant { loto_num: one Boundary, prize_num: lone Boundary, // 状態変化を表現することを目的に付加したフィールド meta_id: one Int, meta_state: one Int } fact { /** meta_state は、-1か0しかない。つまり、事前と事後。*/ all p:Participant | p.meta_state = -1 or p.meta_state = 0 /** ID が等しいふたつAtomがあったら、 それはひとつのAtomの事前状態と事後状態であると考える。 */ all p1,p2:Participant | (p1 != p2 and p1.meta_id = p2.meta_id) => (p1.meta_state != p2.meta_state) } -------------------------------------------------------------- -- くじ引きとしてloto_numがあり、 -- loto_num の値が一番大きかったParticipantに、 -- prize_num、つまり賞品が与えられている。 -------------------------------------------------------------- -- 事前条件 pred BeforeLoto { all participant:Participant | participant.meta_state = -1 => /** 誰も賞品を与えられていないこと。*/ participant.prize_num = none } -- 不変条件 pred Immutable { all participant:Participant | /** 事前状態、事後状態それぞれの中で、IDとloto_numは重複していないこと。 */ participant.meta_state = -1 => all p1,p2:participant | p1 != p2 => eternalUnique[p1,p2] && participant.meta_state = 0 => all p1,p2:participant | p1 != p2 => eternalUnique[p1,p2] /** IDが等しく、状態が異なるAto同士は、loto_numが共通であること。 それ以外は、loto_numは必ず異なる。 */ all p1,p2:Participant | p1 != p2 implies ( (p1.meta_id = p2.meta_id and p1.meta_state != p2.meta_state) implies (p1.loto_num = p2.loto_num) && (p1.loto_num.val = p2.loto_num.val) else (p1.loto_num != p2.loto_num) && (p1.loto_num.val != p2.loto_num.val) ) } pred eternalUnique[p1:Participant,p2:Participant] { (p1.meta_id != p2.meta_id) and (p1.loto_num != p2.loto_num) } /** 状態変化のための条件:loto_numがmaxであること。 そのmaxであるloto_numを返す。 */ fun win_num : Int{ Boundary.(Participant.(Participant<:loto_num)<:val).max } -- 事後条件 pred AfterLoto { /** 事後状態Atomには必ず、対になる事前状態のAtomが存在すること。*/ Participant.( (Participant<:meta_state & Participant->0).Int<:meta_id ) // 抽選後参加者 とそのID、から、IDだけを取り出す in Participant.( (Participant<:meta_state & Participant->-1).Int<:meta_id ) // 抽選前参加者 とそのID、から、IDだけを取り出す && /** loto_num がmaxの者だけが prize_num を持っていること。*/ let winner = loto_num:>(Boundary<:val & Boundary->win_num).Int | Participant<:prize_num in winner } run {Immutable && BeforeLoto && AfterLoto} for 3 but 4 Participant, 3 Int
これで表現できました。

結果がこれです。
Participant1 と Participant2 が、同じidを持っていますので、
これは同じオブジェクトの事前状態と事後状態をあらわしているはずです。
果たしてその通り、Participant1 の meta_state が 0、Participant2 の meta_state が -1 である、ので、
Participant1 は Participant2 が状態変化したものだといえます。両者の loto_num には変化はありません。
そして事前状態の Participant2 は、最大の loto_num を与えられていました。
つまり抽選に当選しているので、事後状態の Participant1 は、prize_num を、ただ一人保持しているわけです。
記述のポイント
今回の仕様記述では、「抽選の事後状態にある参加者」とか、「そのID」を抽出する必要がありました。つまり、
『属性aがXXXであるオブジェクトを得たい』とか、
『属性aがXXXであるオブジェクト、の、属性bを得たい』
といった場合、alloyでどのように記述するかがポイントでした。
これは、alloy的には(集合演算的には)以下のように考えればいいと思います。
- 任意の条件を満たす、全パターンのインスタンス群があって
(これは、Sig名->フィールド名 という書き方で導けます。そこから、ドットジョインを駆使して、望む型の集合を得ます) - 探索したいインスタンス群があって
(これは、フィールドの全集合を、定義域制限 <: で絞って導出)
この両者の積集合が、「条件を満たすインスタンス群」なのですね。
それに気付いたらあとは書くだけでした。

超高速開発コミュニティ モデリング分科会「単独主キー主義」の是非を問う に参加してきました。
去る6月28日、超高速開発コミュニティモデリング分科会「単独主キー主義」の是非を問う
に参加してきました。開催ありがとうございました。
この会は、渡辺幸三さんの最近のブログエントリ
「単独主キー専用環境」と賢くつきあうために
http://watanabek.cocolog-nifty.com/blog/2017/05/post-578f.html
に呼応して開催された勉強会のうちのひとつです。
(※この他に、IT勉強宴会さんでも、5月12日に、「複合主キーは必須なのか?」というテーマで 第55回IT勉強宴会Light というのが開催されていました。行けなくて残念。)
「単独主キー主義」の是非 と言われても、そこから何を想起するか、めいめいバラバラでしょうね。まずは用語を整理します。
これについては明快な答えを、渡辺さんが最初に提示してくれました。
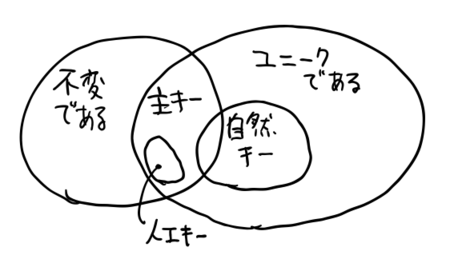
超わかりやすいですね。
そして、「単独主キー専用環境」とは、例えばRubyOnRailsのように、主キーが単独のカラムであることを制約づけた実装環境のことを指しています。
で、通常、データモデリングは、こういった実装環境からはある程度(あるいは厳格に)独立して成立するはずなのですが、そのデータモデリング時点においても、主キーが単独であることを志向する考えかたはあり、それを仮に「単独主キー主義」と呼ぶことにします。
といった前提の上で、「単独主キー主義」の是非について意見を述べ合うという会でした。
参加レポート
まずは「単独主キー主義」の実例として渡辺さんが挙げてくれたのが以下の例でした。ある会社内で、例えば「社員の趣味」を管理したい、という要求があったとして、そのデータ構造は、リレーショナルDBのテーブル上、おそらく以下のようなものなるでしょう。
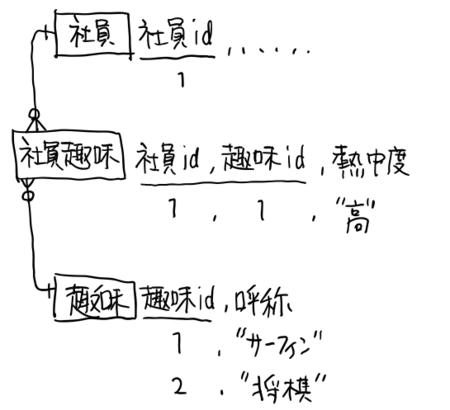
※下線が主キーです。
特に難しいことはないですね。社員のアイデンティファイアと趣味のアイデンティファイアとを複合したものが、"社員趣味"のキーであるという解釈です。
これが、「単独主キー主義」によると、おそらくこうなるであろう、と。

※波括弧は候補キーです。
これもぱっと見、特に違和感ありません。RubyOnRailsでの実装が前提ならこうなるでしょう。しかし問題はその先に潜在しています。{社員id, 趣味id} という、意味上の主キー2項に対して、
ユニーク制約は設定されてはいたとしても、実装上の主キーではない。ので、"趣味id" がなんらかの機会に書き換えられてしまう可能性がある。つまり「不変かつユニーク」という主キーの要件を満たせない状態になっているわけです。
「この場合は、ユニーク制約に加えて、何らかの方法でこれらの項目を更新不可にすればよいのでは?」
と言われれば、その通りではある。とはいえ、そこまでしなきゃいけないんだったら、そもそも無用な代理キーなど無しで実装させてほしい気持ちがある(物理的心理的コストの負荷)。
何より、こうした潜在的な問題に事前に気付いて対策できればまだいいが、
不整合データが実際に発生するまで問題に気付かなかったり、
不整合データが実際に発生してもそれに気付かなかったりしたら
目もあてられないではないか。それって設計したといえるの?
というのが渡辺さんの問題提起でした。
この問題提起を皮切りにディスカッションが始まったんですが、ほんとにどれも興味深い意見ばかりでして
- 単独主キーオンリーの実装からは、確かに業務は分析しにくい。
- データの制約を実現する箇所はリレーショナルDBだけではない。
いろんなアプリケーションが同じDBに自由に接続するという状況は今や稀。
DBを読み書きするアプリケーション層あるいはAPI層がひとつであるのなら、
その層がデータの整合性に責任を持てばいいという作り方もできる。- いまやいろんなデータストアがあり、それらがすべて
リレーショナルモデル的に適切な制約を実装しているとは限らないし。
- いまやいろんなデータストアがあり、それらがすべて
- お客様が要件をなかなか決めきれないことはよくある。その条件下で「とりあえず」の
単独主キーを設定して、モデリング→実装まで進めるという便法はアリかも。
- データモデリングがお客様との共通言語になりにくいという壁はあるよね。
- そこで、"動くモデリングツール"(X-TEA DriverやTALONなど)ですよ。
- 矛盾や間違いに気づきやすいというメリットはやはり強力。
- そこで、"動くモデリングツール"(X-TEA DriverやTALONなど)ですよ。
- Salesforceは、ぱっと見単独主キーの世界だが、エンティティ同士の親子関係を指定するメタ情報がある。
それがあるから厳格なモデリングもできるようになってはいる。
- 例えば社内SNSがいくつもあるような状況下では、適当な単独主キーによる"ユーザー"データが、
あちこちの別システムにに散らばることになる。それらは名寄せして初めてほんもののユーザーデータが
表現できるので、各々のユーザーデータの主キーは仮のものであるのはむしろ自然な姿かも。
- TM(T字形ER手法)では、「社員趣味」はそもそもエンティティとして扱わない。
そこにアイデンティファイアが無いから。エンティティではなく"関係"。
レポートと銘打ってみたものの、ちょっとうまくまとめられそうにない。ので、この箇条書きを提示するにとどめますね。
落穂拾い
ところで、ここで、最初の「社員の趣味」のモデリングについてもういちど検討してみたいと思います。そもそも、{社員id, 趣味id} って、本当にこのエンティティの主キーなんでしょうか?
いや、そもそも、「社員趣味」って何でしょう?
例えば、ある社員は過去に、カメラにものすごく凝ったことがあるとしましょう。それを根拠に「趣味は写真です」と言ってもいいし、あるいは、それは過去のことだから、もう写真は趣味じゃない、という結論でもいい。もう趣味じゃないから放っておくかもしれないし、もう趣味じゃないから、データを更新しないと!って思っているかもしれない。
という状況下で、この社員の趣味について、このテーブルのデータから何が読み取れるだろう?
なんだかすごく曖昧だ。「社員趣味」っていうエンティティが表現しようとしているものが曖昧。
あっ、だから主キーが見つからないんじゃないの?
では試みに、このエンティティのあり方を再定義してみましょう。
もしこれが「社員の趣味」ではなく、「会社の朝礼で、社員が自分の趣味についてスピーチした記録」だとしたら?
その場合、日付なり、朝礼エンティティのアイデンティファイアなりが候補キーに入ってくるでしょう。主キーの再定義です。

この新しい「社員趣味カミングアウト履歴」エンティティは、イベントの記録なので、ユースケース上、書き換えは発生しません。
もちろん、なんらかの理由で趣味idが書き換えられてしまう可能性は依然、ゼロではありませんが、当初の「社員趣味」エンティティよりもだいぶ安定を感じます。
(※そして、イベントというのは、それを参照する何かが居るから記録するわけです。なので、その参照の便宜をはかるための代理キーの存在理由も、若干正当性を増したように思います。)
何より、「社員の趣味」を正しく把握しやすくなりました。
最新の一件を、「現在の趣味」と位置づけるのもいいし、すべての趣味を拾い出した上で、その日付の新しさを見て、趣味群に重み付けをしてもいいし。
主キーについて考えることは、エンティティについて考えること、ひいては、データの目的について考えることと同時点なんですね。
渡辺さんが何気なく出したように見えたこの仮想の事例、こうして軽く掘ってみたら、今回の勉強会の本質にきっちり回帰することになってびっくり。ちょっと出来過ぎじゃないですかね。
まとめると
このようにデータモデリングという作業は、発見が多くて面白いです。問題を解決するプロセスは、問題を理解するプロセスとニアリーイコールなので、その意味でデータモデリングは僕にとっては欠かせないプロセスです。
(※データモデリングを省略する適切なやり方や、その意味が明らかになる日がもし来たら、それはそれで面白そうですが。)
データモデリングに触れたことが無いという技術者の方こそ、こういった勉強会に来てほしいですね。本を読んで独習するよりはるかにはかどるし、エキサイティングですよ。
Learning Alloy: How to Define Objects Generated by Events
If you are software developer, you often implement the object which generated by some other event. But when I represent such objects on Alloy, I always make a mistake. Why? Now I've got the reason. Here it is.
Modeling a "login page".
Generally, authentication in web application uses some session system. In this case, I assume that a session object is generated by "authentication succeeded" event.
Here are the members and their relations.

enum Password {correct, incorrect} some sig UserAccount { password: one correct } sig Session { whose: disj one UserAccount } sig Visitor { signIn: disj lone Session, } sig InputForm { currentVisitor: disj one Visitor, targetUser: one UserAccount, input: targetUser -> one Password } fact { all sess:Session | sess in Visitor.signIn } fact { all vis:Visitor | vis.signIn.whose in currentVisitor.vis.targetUser }
From here, step into the next: defining behavior of LoginForm.
My mistake: "Okay, I will represent a behavior of the LoginForm as 'pred'."
The idea which I came up with first is that I treat a input from users as arguments of function like I used to do in procedural programming. I had sensuously understood that pred is like a function on procedural programming.
pred login[f:InputForm] { f.targetUser.(f.input) = f.targetUser.password implies f.currentVisitor.signIn in Session else f.currentVisitor.signIn = none } check Login { all f:InputForm | !login[f] implies f.targetUser.(f.input) = incorrect && f.currentVisitor.signIn = none }
But this modeling is incorrect. Alloy showed some counter examples. This model allows it to generate a session object despite of the password is incorrect.
result on Evaluator:

I rewrote the pred many times and finally threw away the first perspective.
A different angle
I saw a session object is generated by success of a authentication. So I tried to represent the cause-and-effect relationship between the session object and the authentication in a direct way. It was not a good idea. Because there are no idioms to represent cause-and-effect relationships in Alloy.
Okay, I'll forget the cause-and-effect relationship. Instead of representing it, I wrote variations of the state consisting of valid elements.
fact {
all f:InputForm |
f.targetUser.(f.input) = f.targetUser.password
iff f.currentVisitor.signIn in Session
||
f.targetUser.(f.input) != f.targetUser.password
iff f.currentVisitor.signIn = none
}
Oh, I got it despite of the body of constraints was almost same.

I found it must be written as fact what causes what by throwing away the sense of procedural programming and thinking about state.
The Takeaway
All of event processing contains cause-and-effect relationships. But when you will represent it in Alloy, there is no need to define any cause and effect. All you need is thinking about state. And cause-and-effect relationship can be represented by state.
Future work
I represented the rules of authentication and session in web application from a macroscopic viewpoint. So, what makes the rules work? It is every implemented module of the web application. If I represent the specifications of those modules, I must define not only the rules but also events or state transition by using more complicated techniques.
(Special thanks to Lola A.)
Alloyの seq キーワードの使いどころと注意点
前回扱った仕様の完全版を記述してみます。
<仕様>
- 何枚かの"くちばし" があります。くちばしには、金、銀、黄色、の三種の色分けがあります。
- 金のくちばし1つにつき、缶詰め1つと交換できます。
- 銀のくちばし5つにつき、缶詰め1つと交換できます。
教科書である『抽象によるソフトウェア設計−Alloyではじめる形式手法−』の、
329ページによると、seq というキーワードをつけると、その対象の集合の各要素に番号が振られ、
そしてその集合に対して、配列操作的ないくつかの関数が使えるようになるようです。これだ!
ただし、これ、教科書のとおりに
sig Book {} sig Person { books: seq Book }
こう書いただけだと、
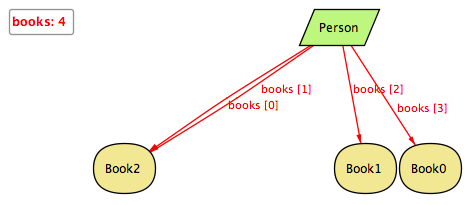
こんなことになってしまいます。
番号と、番号が振られるモデルインスタンスが、1対1にならないんですね。
うーん、これは
sig Person { books: seq Book } { #(books.inds) = #(books.elems) }
こうして、個数を制限することで回避することにします。inds() は、indexつまり配列の添え字だけ取り出す関数、
elms() は、seq が指し示すモデルインスタンスだけを取得する関数です。(他にもっといい回避方法あるかな?)
さて、これで seq キーワードを使う準備ができました。
今回の記述では、「缶詰め」をいくつか、フィールドとして保持する状態空間があるとして、
そのフィールドに対して、seq をつけてみます。ひとつのフィールドに対して、シーケンス番号つきの別な
アクセス経路を開いたかたちです。こうすることで、
”その缶詰め群のうち、n番目からm番目まで”
という指定で、要素を取得することでできるようになります。(subseq 関数を使用。)
つまり、手持ちのくちばしが、
GOLD 1枚、SILVER 2枚、YELLOW 5枚、だったら、対象の缶詰め配列の、0番目から0番目までが自分の取り分です。
GOLD 1枚、SILVER 7枚、YELLOW 15枚、だったら、対象の缶詰め配列の、0番目から1番目までが自分の取り分です。
以下がその全文です。
enum Color {GOLD, SILVER, YELLOW} some sig Beak { color: one Color } some sig Can {} -- 取得したCanを保持した状態空間 abstract sig Bag { have : some Can } one sig MyBefore extends Bag {} one sig MyAfter extends Bag {} one sig Stock extends Bag { haveAccessor: seq have } { // ※番号とインスタンスの組を1対1にするために #(haveAccessor.inds) = #(haveAccessor.elems) // ※have と、haveAccessor が指すものは同一。 have = haveAccessor.elems } // ※状態の定義にかかわるfact fact theirsOrMine { // ※取得済み缶詰めと、未取得缶詰めは互いに素 MyBefore.have & Stock.have = none } fact whatIsAfter { all stock:Stock, before:MyBefore, after:MyAfter | getCan[stock] + before.have = after.have } -- 定数 one sig Number { silverRate : one Int, goldRate : one Int } { silverRate = 5 goldRate = 1 } -- くちばしと缶詰めの交換ロジック fun getCan(stock:Stock) : some Can { stock.haveAccessor.subseq[ 0, plus[ div[ #(color & (Beak -> SILVER)), Number.silverRate ], div[ #(color & (Beak -> GOLD)), Number.goldRate ] ].minus[1] ].elems } // ※ご都合主義的に、在庫を潤沢に確保 fact 在庫を潤沢に確保 { #(Stock.have) >= #(Beak)} // ※くちばしもある程度数確保 fact くちばしもある程度数確保 { #(Beak) >= 7} // run {} for 8

このように、
「個数」を指定した配列操作を表現したいときは、seq キーワードをつけると、s.subseq() が使えて便利でした。
seq キーワードを使うときは、番号と、番号が振られるモデルインスタンスが、1対1になるように細工が必要ではありますが。
Alloyで、rubyのArray#select() みたいな定義を書く
ruby のユーザーにとって、Array#select() などの、「ブロック」の概念を化通用したメソッドは強力に便利です。
こんなふうに。
arr = "second baseman", "third baseman", "first baseman", "shortstop" # => ["second baseman", "third baseman", "first baseman", "shortstop"] arr.select{|elm| elm =~ /baseman/}.sort # => ["first baseman", "second baseman", "third baseman"]
そしてAlloy で仕様定義をする中で、ruby の Array#select() のような発想をしている場面が
けっこうあることに気づきました。つまり、その集合のなかで
“XXXX という性質を持つ、部分集合”
を記述するときです。
ここでは、“XXXX という性質” というのは、その属性によって決定づけられるものだとして、
例えば、以下の様な仕様を記述することを考えてみましょう。
<仕様>
- 何枚かの"くちばし" があります。くちばしには、金、銀、黄色、の三種の色分けがあります。
- 金のくちばし1つにつき、缶詰め1つと交換できます。
- 銀のくちばし5つにつき、缶詰め1つと交換できます。
この仕様の一部を記述してみました。
open util/integer enum Color {GOLD, SILVER, YELLOW} some sig Beak { color: one Color } some sig Can {} abstract sig Number { val: one Int } one sig RateSilver extends Number {} { val = 5 } one sig RateGold extends Number {} { val = 1 } // SILVERのくちばしと、缶詰めの交換ルール fun silverToCanNum(b:Beak) : one Int { div[#(color & (b -> SILVER)), RateSilver.val] } // とりあえず多めにインスタンスを表示 fact { #(Can) >= 4 && #(Beak) >= 7} run {} for 8 but 8 Beak
・"&” は、積集合を求める演算子です。
・"color" で、Beak と Color の、(実体化された)組 たちが表され、
・"b -> SILVER" で、Beak が皆 SILVER であることを仮想した組 たちが表されています。
このふたつの集合の積集合をとることで、
”色がSILVERのくちばし群”
が表現できました。

そしてこれを実行した、Alloy の Evaluatar 上で
silverToCanNum[Beak]
を、実行すると、ちゃんと
{1}
が返ってきました。
ruby の「ブロック」の概念を覚えた時は、脳の新しい扉が開いた感じがしましたね。
あれが関数型言語とか形式仕様記述の入り口だったのかもしれません。
【訂正】Alloy Analyzer で、あの格言をモデリングする その3〜石の上にも三年って、具体的に何年から何年まで?〜
前回のモデリング、を何度もいじくり回しているうちに、間違いが2点見つかったので、まず訂正します。
一つ目は、MinInterval。
当年と座り始めた年との間には、最低3目盛り、距離でいうと、4離れていないといけない
という理由で、
one sig MinInterval { val: one Int } { val = 4}
というシグネチャと、それを使った制約を使っていたんですが、これは要らなかったですね。
どんな事例を提示するか(出来るか)は、Alloy に任せればそれでよかった。
もちろんそのためには、数値のスコープは、仕様に合わせて管理しないといけないわけですが。
二つ目は、算術演算の使用について。
4 Int というスコープ内で、例えば、6.minus[-5] っていう減算が出てきたとき、解である 11 が、
スコープ外になってしまうので、期待と違う動作になってしまうことがわかりました。
今回の仕様でいうと、減算しか使っていないので、もし登場する Int がどれも正の数であれば、
こういことが起こる心配はとりあえず排除できるんで、これは fact を直すことで対処することにします。
修正したモデリングの全文は、これです。
abstract sig Border { val: one Int } one sig BorderThree extends Border {} { val = 3 } // 0〜7 をアサイン可能。 one sig BorderZero extends Border {} { val = 0 } abstract sig Year { val: one Int } one sig ThisYear extends Year {} sig SinceYear extends Year { whose: one Craftman } sig Craftman { sinceYear: one SinceYear } abstract sig Career { guys: set Craftman } one sig Rookie, FullGrown extends Career {} fact generic { // CraftmanのsinceYearとして作用していないSinceYearは、不要。 sinceYear = ~whose // rookieGuysとfullGrownGuysは互いに素。 disj[Rookie.guys, FullGrown.guys] // 開始年は過去である、等。 all sYear:SinceYear, tYear:ThisYear | tYear.val >= sYear.val && sYear.val >= BorderZero.val } fact bizLogic { all c:Craftman, r:Rookie, f:FullGrown, y:ThisYear, b:BorderThree | let rGuys = r.guys, fGuys = f.guys | y.val.minus[c.sinceYear.val] > b.val implies c in fGuys else c in rGuys } run {} for 4 Int, 4 Craftman, 6 Year
以上、過去エントリの訂正でした。